Driver-based planning models are a funny thing — we either love them, or we hate them. (And it seems most hate them!) So why do driver-based planning models get such a strong reaction? Typically it’s because of an experience with a bad driver-based model.
I’ve built many planning models — some driver-based (bottom-up), but mostly top-down. So what should you consider as you build a driver-based model? Here are some suggestions to approach them in a better way:
Keep the big picture in mind
In any planning process, we need to stay focused on the big picture. We aren’t going to develop a model that will forecast sales revenue within 0.5% and $10,000 — it’s just not realistic.
Incorporate the right level of detail
One of the biggest mistakes is that the details within the model are more than what’s necessary. What do I mean by that? Usually we are building a model with driver components so detailed we lose sight of the purpose of our plan. Users might abandon the plan altogether as a result.
Let’s consider the following example in which you’re building a driver tree to forecast the cost per unit of a disk drive. Your inputs account for the daily price of diesel in southern Indiana going back 14 years. This information you use to forecast the cost of freight. An absurd example perhaps — but it’s easy to quickly go down a rabbit hole, especially with detail-oriented people. (I’m looking at you, accountants.)
How can we ensure that we aren’t getting too far into the weeds? A fishbone diagram can help us visualize the details.
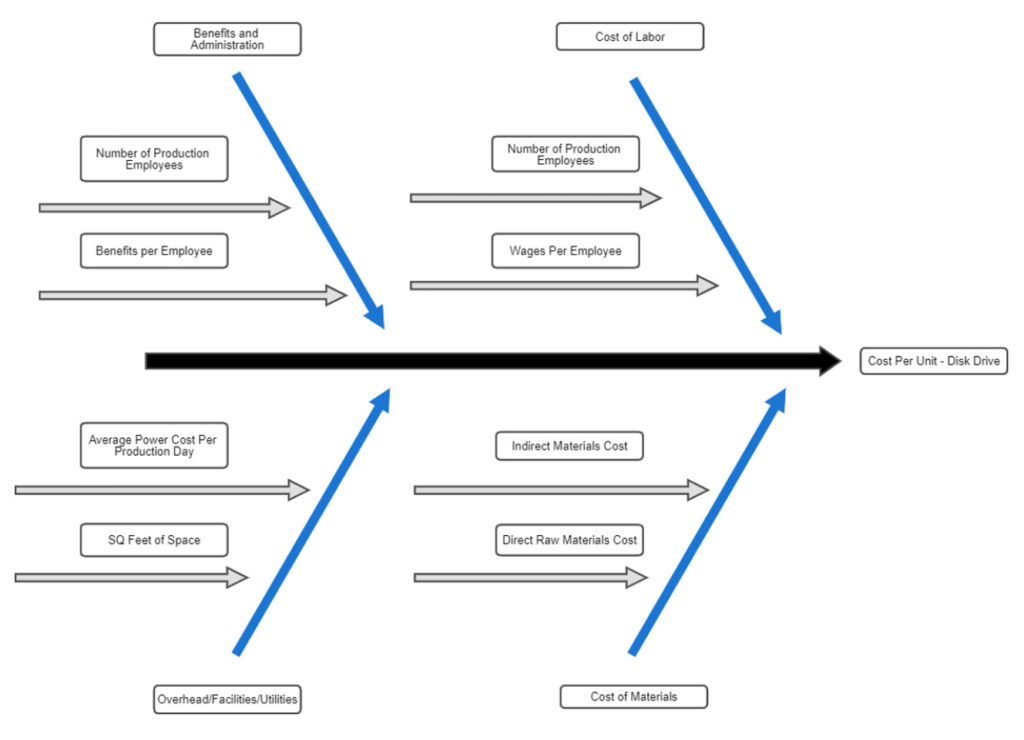
That’s not to say that models with too few details are good either. At the end of the day, you have to develop a model that’s accurate and sustainable.
Make the model flexible
One consistent issue associated with driver-based models is they are constructed in a way that makes them too rigid. What do I mean by that? Here’s a real-world example. In one driver-based model I worked with (as a user, not the creator) we were only able to forecast labor by changing detailed labor inputs. We could change the labor rate by cost center, we could change the number of hours worked, and we could change benefit and vacation rates, but that was it. When the regional controller was told during the final review with executives that he needed to increase or decrease labor costs, all he could do was change the labor rate by cost center.
Why is this a problem? The labor rate by cost center was a pretty accurate number. Now when the regional staff reviewed the plan all they could see was this glaring inaccuracy.
Another issue with rigid models is they are often built based on modeling sales or expenses from prior periods. You could use 12 or 24 months — it doesn’t matter. These models work well when you have consistent operations with little fluctuation. However, when new divisions or product lines come online, these models fall flat because they are based on historical actuals that don’t exist.
Every driver-based planning model I build has multiple “relief valves.” These are various methods in which users can alter the outcomes of a modeled result. The inputs are always clear and are intended to be part of the system, not a hack that is erased every time a base assumption is changed.
Share and expose the build of the model
One sure way to get low utilization of a planning model or process is to make it a black box. A black box is a model in which users feed in inputs they may or may not understand — a result comes out with no explanation of how that number is derived. These obscure systems turn planners and accountants into robots that take no responsibility for the planned numbers.
Not everyone in your organization will become an expert in the development and configuration of your planning system. That’s why it’s critical to expose as much of the process as possible to users. Instead of creating an input template that only consumes drivers, offer feedback that shows how the system will use the inputs to arrive at a planned cost or revenue.
It’s all about our perception
Even the best model won’t provide an accurate answer to every question. But if we view a well-built driver-based model as a tool to give us 90% of our plan, and we contribute the remainder — maybe we’ll grow to love driver-based models.



